Анализ Python
В ближайшее время в инструмент Svace будет добавлена первая версия поддержки языка Python. Этот язык активно используется во многих проектах, написанных на других языках, так и для создания самостоятельных крупных проектов.
В настоящий момент инструмент Svace поддерживает статический анализ исходного кода на языках C, C++, C#, Java, Kotlin и Go. Все перечисленные языки отличаются статической типизацией, что позволяет в большинстве случаев определять типы объектов. В отличие от них Python является языком с динамической типизацией, что требует дополнительных усилий со стороны статического анализа.
Другое важное отличие языка Python заключается в подходе Svace к анализу, при котором происходит перехват команд компиляции, выполняемых во время сборки проекта. Процесс анализа Svace состоит из двух этапов: сборки проекта с сохранением промежуточного представления для перехваченных компилируемых файлов и, собственно, анализа промежуточного представления. Python является интерпретируемым языком и не требует компиляции исходного кода. Поскольку для проекта на языке Python, компиляция не требуется, в этом случае на этапе сборки Svace сканирует директорию с исходным кодом и строит промежуточное представления для всех обнаруженных файлов.
Процесс сборки на данный момент выглядит следующим образом (зелёным цветом выделены элементы, добавленные для поддержки анализа Python):
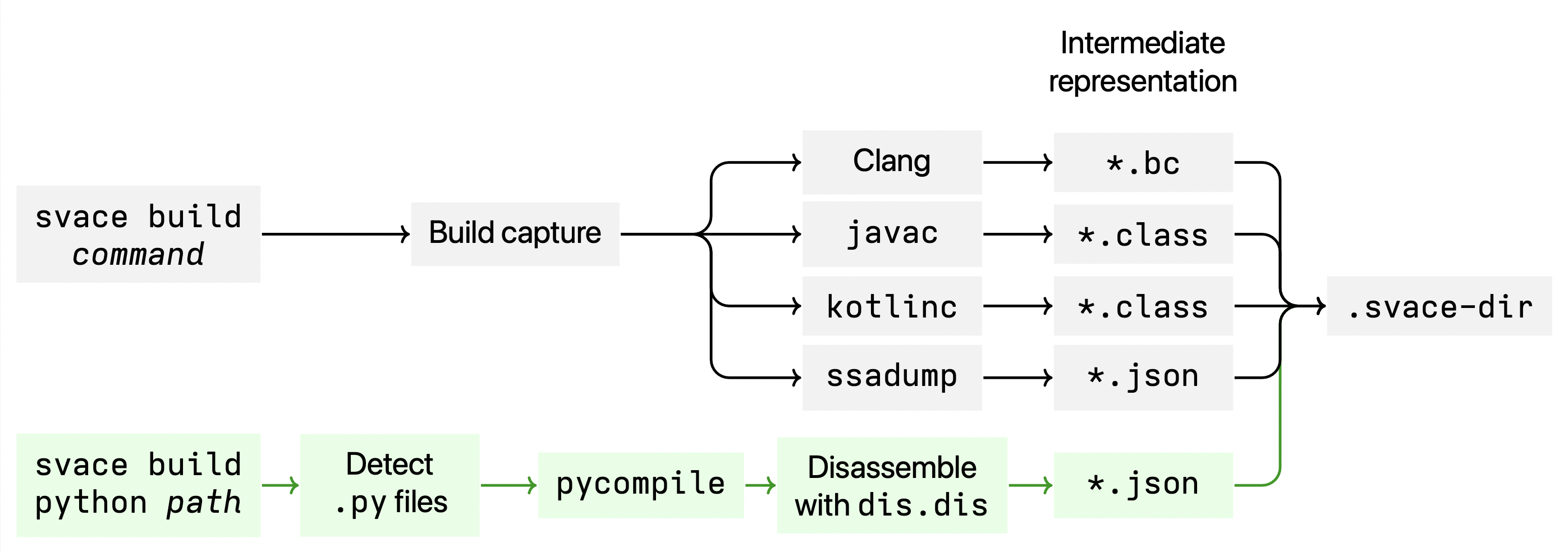
В первой версии мы
- добавили интеграцию с инструментом Mypy,
- добавили анализ на основе абстрактного синтаксического дерева, который выполнен на новом компоненте Svace
UAST, - добавили построение внутреннего представления для основного анализа. В настоящий момент поддерживается детектор DIVISION_BY_ZERO.EX.
Запуск
Как и для других языков, для запуска анализа Python необходимо инициализировать Svace, запустить сборку проекта и анализ. В команде сборки нужно указать ключевое слово --python и директорию, содержащую файлы с исходным кодом:
svace init
svace build --python ${DIRECTORY}
svace analyze
Компоненты
Mypy
Если у пользователя установлен инструмент Mypy, будет запущен анализ и его результаты будут включены в общий набор предупреждений. Для удобства эти предупреждения имеют префикс MYPY.
Например, MYPY.LIST_ITEM в проекте Pandas 2.0.0 pandas/pandas/util/_tester.py:
def test(extra_args: list[str] | None = None) -> None:
pytest = import_optional_dependency("pytest")
import_optional_dependency("hypothesis")
cmd = ["--skip-slow", "--skip-network", "--skip-db"]
if extra_args:
if not isinstance(extra_args, list):
# List item 0 has incompatible type "List[str]"; expected "str" [list-item].
extra_args = [extra_args]
cmd = extra_args
UAST
Поиск ошибок на абстрактном синтаксическом дереве производится с помощью нового компонента UAST (unified abstract syntax tree).
Например, SIMILAR_BRANCHES в проекте Pandas 2.1.0 pandas/io/excel/_base.py:
if isinstance(sheet_name, list):
sheets = sheet_name
ret_dict = True
elif sheet_name is None:
sheets = self.sheet_names
ret_dict = True
# Identical branches in conditional node.
elif isinstance(sheet_name, str):
# First branch.
sheets = [sheet_name]
else:
# Second branch.
sheets = [sheet_name]
UAST.EMPTY_CATCH в проекте Pandas 2.1.0 pandas/plotting/_core.py:
try:
kwargs[kw] = data[kwargs[kw]]
# An exception is caught, but not processed.
except (IndexError, KeyError, TypeError):
pass
Svace Engine
Для основного движка анализа реализовано сохранение промежуточного представления. В настоящий момент для языка Python поддержан только один детектор.
Например, DIVISION_BY_ZERO.EX в проекте Pandas 2.1.0 pandas/tests/arrays/floating/test_contains.py:
import numpy as np
import pandas as pd
def test_contains_nan():
# GH#52840
arr = pd.array(range(5)) / 0 # Division by zero.
assert np.isnan(arr._data[0])
assert not arr.isna()[0]
assert np.nan in arr
В следующем примере в проекте Pytorch деление на ноль корректно обрабатывается, однако этот пример демонстрирует возможности анализа обнаруживать межпроцедурные ошибки. Некоторые строки были удалены в угоду читаемости (оригинальный код на GitHub)
def print_file_summary(
covered_summary: int, total_summary: int
) -> float:
try:
# Potential division by zero.
coverage_percentage = 100.0 * covered_summary / total_summary
except ZeroDivisionError:
coverage_percentage = 0
# Skipped.
def print_file_oriented_report(
covered_summary: int,
total_summary: int,
) -> None:
coverage_percentage = print_file_summary(
covered_summary, total_summary # Transfer `total_summary`.
)
# Skipped.
def file_oriented_report(
covered_lines: Dict[str, Set[int]],
uncovered_lines: Dict[str, Set[int]],
) -> None:
with open(os.path.join(SUMMARY_FOLDER_DIR, "file_summary"), "w+") as summary_file:
covered_summary = 0
total_summary = 0
for file_name in covered_lines:
covered_count = len(covered_lines[file_name])
total_count = covered_count + len(uncovered_lines[file_name])
covered_summary = covered_summary + covered_count
total_summary = total_summary + total_count
print_file_oriented_report(
covered_summary,
total_summary, # Transfer `total_summary`.
)
В данном примере функция file_oriented_report обходит массив covered_lines и записывает в переменную total_summary общее количество найденных строк. Если массив пустой, то переменная total_summary будет иметь нулевое значение. Вызов функции print_file_oriented_report передаст эту переменную в функцию print_file_summary, которая в свою очередь будет использовать переменную total_summary как делитель.