Python analysis
In the near future the first version of Python programming language support will be integrated into Svace. This language is both used in many projects written on other languages and projects created solely on Python.
At the current state Svace supports source code static analysis of projects written in C, C++, C#, Java, Kotlin and Go programming languages. All the mentioned languages differ from Python by using static typing, which allows, in most cases, determine object’s type. Python, on the other hand, is a language with dynamic typing, which requires additional efforts from static code analyzer.
Another important difference in the Python language is in the way Svace handles the part of the analysis, where compilation commands, which are executed during the project build stage, are intercepted. Svace analysis consists of two stages: project building while storing all the intermediate representation for all the compiled files and, of course, analysis of said representation. Python is an interpreted language and does not require source code compilation. So instead Svace scans project’s directory with the source code and constructs intermediate representation for all the found files.
The building process, at the current state, looks like this (elements related to Python analysis are highlighted with green):
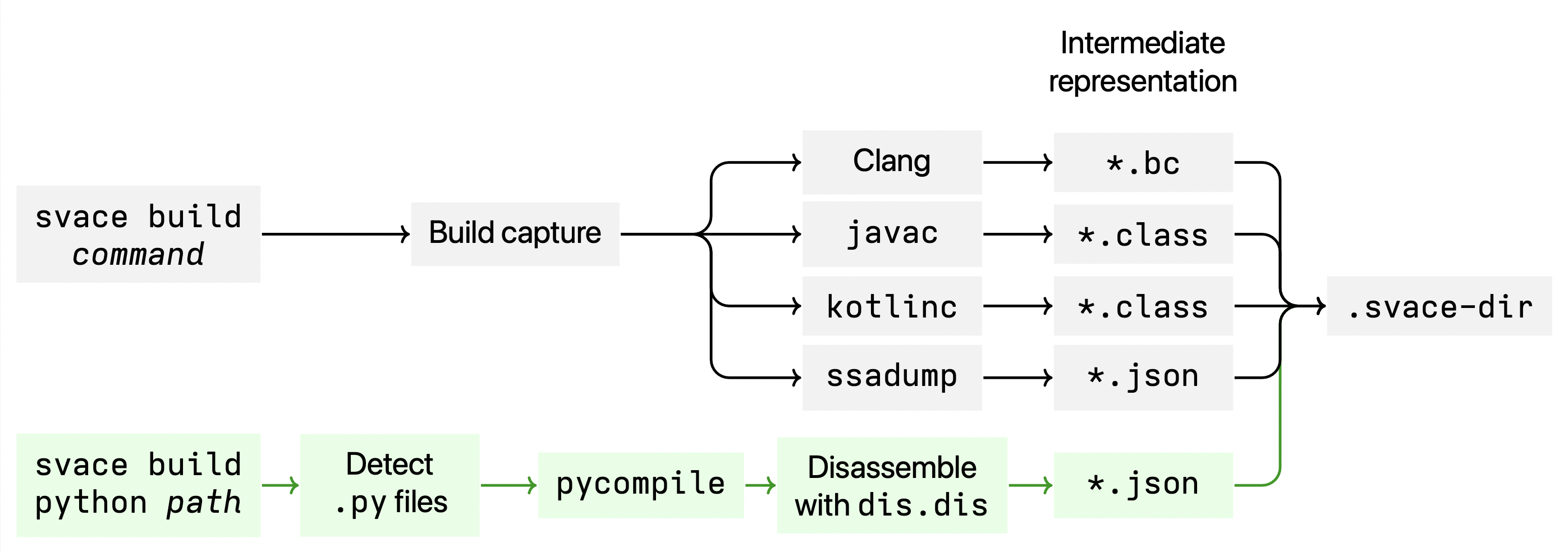
In the first version we have incorporated
- Integration with Mypy tool,
- Abstract syntax tree analysis, based on the new Svace
UASTcomponent, - Construction of the inner representation for the main analysis. At the current state we support DIVISION_BY_ZERO.EX detector.
Analysing
As for the other languages, to analyze Python you have to initialize Svace, run project build and analysis. In the build command you have to specify keyword --python and directory with the source code:
svace init
svace build --python ${DIRECTORY}
svace analyze
Components
Mypy
If the user has Mypy tool installed, it’s analysis will also be run and it’s results will be included into Svace warnings with MYPY prefix.
def test(extra_args: list[str] | None = None) -> None:
def test(extra_args: list[str] | None = None) -> None:
pytest = import_optional_dependency("pytest")
import_optional_dependency("hypothesis")
cmd = ["--skip-slow", "--skip-network", "--skip-db"]
if extra_args:
if not isinstance(extra_args, list):
# List item 0 has incompatible type "List[str]"; expected "str" [list-item].
extra_args = [extra_args]
cmd = extra_args
UAST
Error search based on an Abstract Syntax Tree uses new Svace component named UAST (Unified Abstract Syntax Tree).
For example SIMILAR_BRANCHES in the Pandas 2.1.0 project pandas/io/excel/_base.py:
if isinstance(sheet_name, list):
sheets = sheet_name
ret_dict = True
elif sheet_name is None:
sheets = self.sheet_names
ret_dict = True
# Identical branches in conditional node.
elif isinstance(sheet_name, str):
# First branch.
sheets = [sheet_name]
else:
# Second branch.
sheets = [sheet_name]
UAST.EMPTY_CATCH in the Pandas 2.1.0 project pandas/plotting/_core.py:
try:
kwargs[kw] = data[kwargs[kw]]
# An exception is caught, but not processed.
except (IndexError, KeyError, TypeError):
pass
Svace Engine
For the main analysis engine intermediate representation is stored. At the current moment only one detector is supported for Python, which was mentioned earlier.
For example DIVISION_BY_ZERO.EX in the Pandas 2.1.0 project pandas/tests/arrays/floating/test_contains.py:
import numpy as np
import pandas as pd
def test_contains_nan():
# GH#52840
arr = pd.array(range(5)) / 0 # Division by zero.
assert np.isnan(arr._data[0])
assert not arr.isna()[0]
assert np.nan in arr
In the following example in the Pytorch project division by zero is handled correctly, but this case demonstrates analysis capability to find interprocedural errors. Some lines have been removed in order to make the code more readable (original source code on GitHub):
def print_file_summary(
covered_summary: int, total_summary: int
) -> float:
try:
# Potential division by zero.
coverage_percentage = 100.0 * covered_summary / total_summary
except ZeroDivisionError:
coverage_percentage = 0
# Skipped.
def print_file_oriented_report(
covered_summary: int,
total_summary: int,
) -> None:
coverage_percentage = print_file_summary(
covered_summary, total_summary # Transfer `total_summary`.
)
# Skipped.
def file_oriented_report(
covered_lines: Dict[str, Set[int]],
uncovered_lines: Dict[str, Set[int]],
) -> None:
with open(os.path.join(SUMMARY_FOLDER_DIR, "file_summary"), "w+") as summary_file:
covered_summary = 0
total_summary = 0
for file_name in covered_lines:
covered_count = len(covered_lines[file_name])
total_count = covered_count + len(uncovered_lines[file_name])
covered_summary = covered_summary + covered_count
total_summary = total_summary + total_count
print_file_oriented_report(
covered_summary,
total_summary, # Transfer `total_summary`.
)
In this example file_oriented_report function goes through covered_lines array and stores the amount of lines found into total_summary variable.
If the given array is empty, then total_summary will be equal to zero.
Call of the print_file_oriented_report passes the variable into the print_file_summary function, which uses total_summary as a divider.